A Scoping Review of Supervised Machine Learning Techniques in Predicting the Prevalence of Type 2 Diabetes Mellitus
Predicting T2DM Prevalence using Machine Learning
Abstract
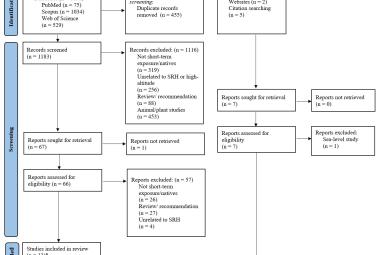
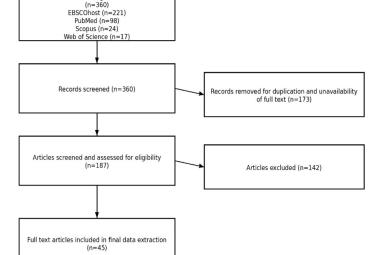
It is crucial for medical practice to navigate from solely dependent on conventional data-analytical approaches for disease screening, diagnostics, and treatment plans to decisions that are configured rapidly through big data analytics from artificial intelligence algorithms. The fog- and edge-computing architectures built within the huge healthcare database systems would allow the applications of machine learning (ML) algorithms for disease predictions and forecasting capacities. This scoping review appraised the use of multiple ML methods for type 2 diabetes mellitus (T2DM) prediction. Search engines used were IEEE Xplore, JSTOR, PubMed, Sage, Scopus, Wiley, and WOS. Inclusion criteria included articles published within the past six years, open access and studies that focused on T2DM only. Out of 41 studies included, the most used ML method was Random Forest (n=33) and the most occurred best ML model (n=13). Customised Ensemble ML method adapted to the dataset was found to show the highest accuracy. However, there were insufficient study areas and samples in Southeast Asia countries, as there were differences in demographics and culture that affect the T2DM risk factors where computational resource and systems development were limited. We conclude ML methods can predict T2DM, from the system’s perspective its intra-operability is viable for use in healthcare systems.
Keywords :
Prediction,
supervised machine learning,
type 2 diabetes mellitus,
Abstrak
Adalah penting bagi pihak perubatan untuk mengemudi perawatan daripada bergantung semata-mata pada pendekatan analisis data konvensional untuk saringan penyakit, diagnostik dan rawatan kepada keputusan yang dikonfigurasikan dengan pantas melalui analisis data besar daripada algoritma kecerdasan buatan (AI). Seni bina pengkomputeran “kabus” dan “tepi” yang dibina dalam sistem pangkalan data penjagaan kesihatan dan pengawasan yang besar membolehkan aplikasi algoritma pembelajaran mesin (ML) untuk ramalan penyakit dan kapasiti ramalan. Semakan tinjauan ini menilai penggunaan pelbagai kaedah ML untuk meramal T2DM. Enjin carian yang digunakan ialah IEEE Xplore, JSTOR, PubMed, Sage, Scopus, Wiley dan WOS. Kriteria kemasukan termasuk artikel yang diterbitkan dalam tempoh enam tahun lalu, akses terbuka dan kajian memfokuskan pada Diabetis Melitus Jenis 2 (T2DM) sahaja. Daripada 41 kajian, kaedah ML yang paling banyak digunakan ialah Random Forest (n=33) dan juga model ML terbaik yang paling banyak dijalankan (n=13). Kaedah ML Customised Ensemble yang disesuaikan dengan set data didapati menunjukkan ketepatan tertinggi. Walau bagaimanapun, kawasan kajian dan sampel tidak mencukupi di negara Asia Tenggara, kerana terdapat perbezaan dalam demografi dan budaya yang mempengaruhi faktor risiko T2DM di mana sumber pengiraan dan pembangunan sistem adalah terhad. Kami menyimpulkan kaedah ML mampu meramal T2DM, dari perspektif sistem kebolehoperasian intranya yang berdaya maju untuk digunakan dalam sistem penjagaan kesihatan.
Kata Kunci :
Diabetis melitus jenis 2,
pembelajaran mesin,
ramalan,
Correspondance Address
Associate Professor Dr. Khairul Nizam Abdul Maulud. Earth Observation Centre, Institute of Climate Change, Universiti Kebangsaan Malaysia, 43600 Selangor Darul Ehsan, Malaysia. Tel: +603-8921 6767 Email: knam@ukm.edu.my